
Logging in to NSF XSEDE Stampede
Before starting this module, all students in AML610 were asked to apply for an XSEDE user portal account by going to this link and filling in the form, and choosing a username.
Now I will show you how to use ssh to login to the Stamped account we have been allocated for this course. Type
ssh <your username>@stampede.tacc.xsede.org
Note that your TACC password is not necessarily the same as your XSEDE user portal password. If you can’t login, go to the TACC portal webpage, and ask to reset your password.
To log off of Stampede, type
exit
Logging on to the XSEDE user portal
If we had allocations on multiple XSEDE high-performancing computing platforms (Stampede is just one of them), we could use the XSEDE user portal as a means to easily access them all. To login to the XSEDE user portal, type
ssh -l <your username> login.xsede.org
This also works
ssh <your username>@login.xsede.org
To logon to Stampede from there, type:
gsissh -p 2222 stampede.tacc.xsede.org
When you want to logoff (of either Stampede, or the user portal), type
exit
Transferring files to and from XSEDE
To transfer files from your personal laptop to Stampede, you could just use scp
localhost% scp <filename> <username>@stampede.tacc.utexas.edu:/path/to/project/directory
However, while using scp is possible to and from XSEDE resources, XSEDE prefers instead that you use the Globus application they have developed, rather than scp, because Globus is designed to be more efficient for the transfer of large files.
You need to set up the Globus application before you can use it: go to the page www.globus.org/globus-connect-personal and select the operating system for your laptop/desktop. Click on your operating system under “Downloads” and follow the step-by-step instructions to set up a Globus user account (“Sign Up with Globus” at https://www.globus.org/SignIn#noauthfor=%2Fxfer%2FManageEndpoints).
Once you have set up the Globus account and logged in, you need to set up a “key” that will be used to communicate between your laptop and XSEDE. This is what the page looks like:
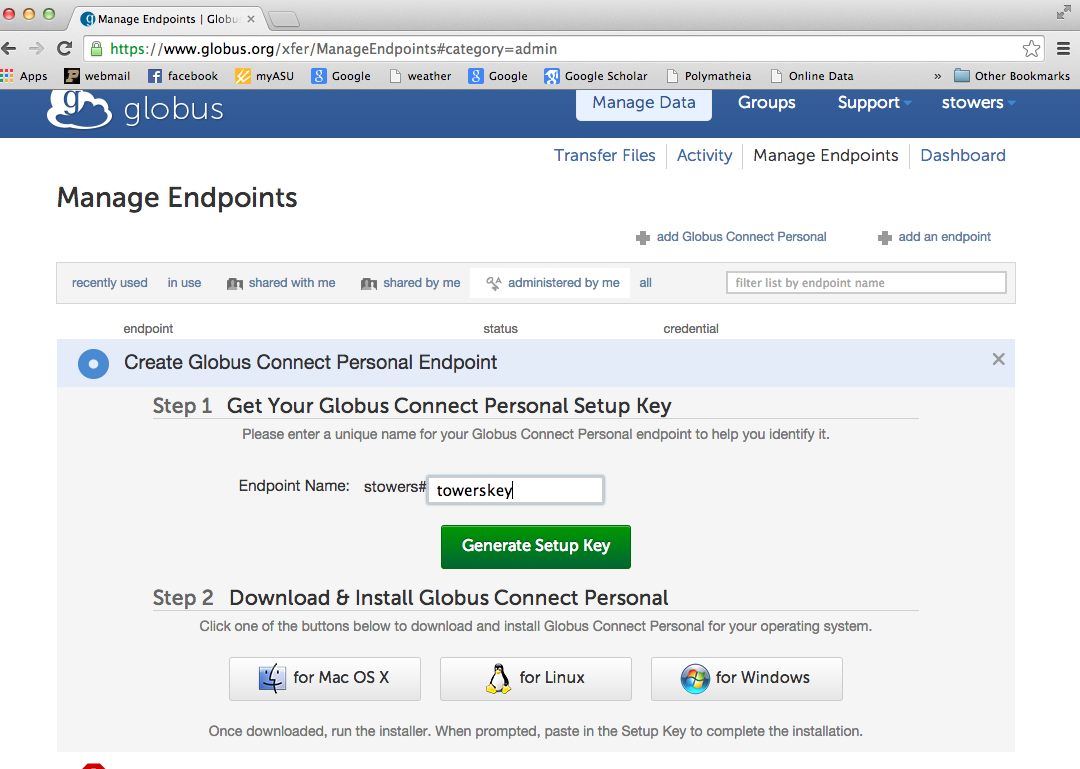
You can name your key whatever you like, but remember what you called it for future reference when transferring files (write it down somewhere). Once you enter your key name and click “Generate Setup Key”, it will give you a Setup Key that you need to copy.
Now download and install Globus for the operating system of your choice by clicking on the appropriate link on that page.
Now run the Globus application on your laptop, and paste in the Setup Key that you had copied earlier.
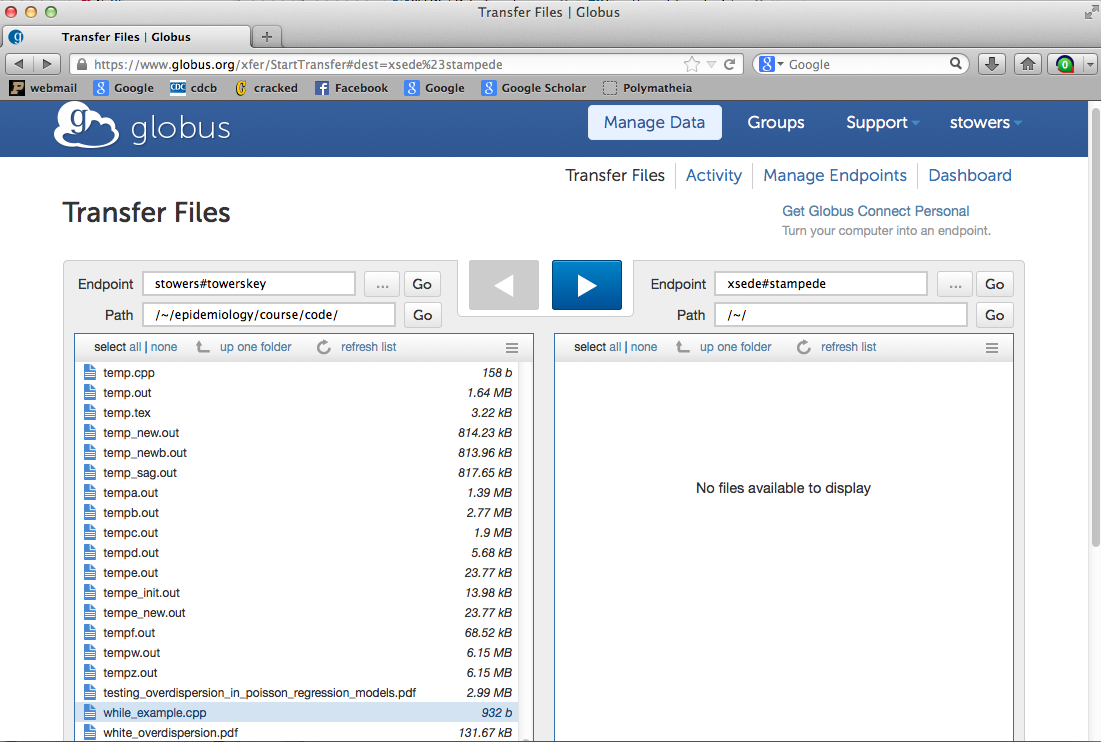
To transfer files to Stampede, startup the Globus application, and go to Manage Data (or Web: Transfer Files). For the first endpoint, enter your username followed by a hash mark and then the Setup Key name you had entered earlier when you set up Globus. This will pull up all the files on your laptop. Select the one you want. For the other endpoint, use xsede#stampede:
Compiling C++ programs on XSEDE Stampede
So far in this course on our laptops we’ve been using the gcc or g++ compilers to compile our C++ programs. For Stampede, there is a special compiler that they want you to use for C++ compilers called icpc. This involves just a simple change to your makefiles, where you substitute in icpc for g++.
You’ll notice in the transfer example above, I transferred the while_example.cpp program to Stampede. After the transfer, I logged onto XSEDE Stampede and typed
icpc -o while_example while_example.cpp
Note that I could run the while_example program from the command line on Stampede, but that is not what Stampede is meant for (so don’t do it, because you’ll get your account suspended!). Stampede is meant to be used as a distributed computing system, where you can execute many copies of the same program on several different processors at the same time. Stampede is directed to do this via what is known as a batch submission script.
Some background: What is a batch job?
From the NSF XSEDE website:
A batch job is a computer program or set of programs processed in batch mode. This means that a sequence of commands to be executed by the operating system is listed in a file (often called a batch file, command file, or shell script) and submitted for execution as a single unit. The opposite of a batch job is interactive processing, in which a user enters individual commands to be processed immediately.
In many cases, batch jobs accumulate during working hours, and are then executed during the evening or another time the computer is idle. This is often the best way to run programs that place heavy demands on the computer.
On high-performance compute clusters, users typically submit batch jobs to queues, which are classes of compute nodes, managed by a resource manager, such as LoadLeveler and TORQUE (also known as Portable Batch System). Frequently, clusters employ separate job schedulers, such as Moab, to dispatch batch jobs based on the availability of compute resources, job requirements specified by users, and usage policies set by cluster administrators.
To see which resource managers and job schedulers are used on various Extreme Science and Engineering Discovery Environment (XSEDE) clusters, seeOn XSEDE compute systems, what applications are used for scheduling jobs?
In the next module, we’ll discuss how to run an example job in batch on XSEDE.