
Category Archives: ASU AML610 Fall 2014
How to scp and ssh without prompting for password
Reply
When you use scp to copy files from Unix machine to Unix machine, it asks you for your password. Ditto when you use ssh. When copying a lot of files, this can get tedious. Continue reading
Example using Negative Binomial likelihood for model parameter optimization
In this past module, we discussed using the Pearson chi-squared statistic to determine the best-fit parameters of an SIR model to influenza B data from the 2007-08 Midwest flu season. In this module, we will discuss how to find the best-fit parameters using the Negative Binomial likelihood instead.
Correcting for over-dispersion when using Pearson chi-squared
In this past module, we discussed the various merits and applicability of the Least Squares, Pearson chi-square, Poisson likelihood, and Negative Binomial likelihood statistics.
And in this past module we discussed how we can use the graphical Monte Carlo method (aka fmin plus a half method) to determine the one-std deviation confidence interval on our parameter hypotheses when using a likelihood statistic, and we also discussed how the Least Squares and Pearson chi-square statistics can be converted to likelihood statistics.
Submitting jobs to the ASU A2C2 ASURE batch computing system
The AML610 Fall 2014 course has received an allocation of 10,000 CPU hours on the A2C2 Asure batch computing system. Students in the course have received an email from me describing how to sign up for an Asure account under this allocation.
Another example C++ program to fit model parameters to data
In a past module, we examined how we could use methods in the R deSolve to fit the parameters of an SIR model to confirmed cases of influenza B in the Midwest region during the 2007-2008 flu season (the data were obtained from the CDC). In that module, we used a Least Squares goodness-of-fit estimator. Continue reading
An example C++ program to fit model parameters: using XSEDE
In Homework#7 of the 2014 fall AML610 course, we discussed an example where we had a time series of data for a disease vector, V, that can spread disease to a human population. Once the humans catch the disease, they recover after 1/gamma days and moved to the recovered compartment.
A C++ class for numerically solving ODE’s
In previous modules, we have described how to use methods in the R deSolve library to numerically solve systems of ordinary differential equations, like the SIR model. The default algorithm underlying the functions in the deSolve library is 4th order Runge-Kutta method, which involves an iterative process to obtain approximate numerical solutions to the differential equations. Euler’s method is an even simpler method that can be used to estimate solutions to ODE’s, but 4th order Runge-Kutta is a higher order method that is more precise. Continue reading
Using the NSF XSEDE batch computing system
Link
Logging in to NSF XSEDE Stampede
Before starting this module, all students in AML610 were asked to apply for an XSEDE user portal account by going to this link and filling in the form, and choosing a username. Continue reading
Protected: AML610 Fall 2104 project list
Estimating parameter confidence intervals when using the Monte Carlo optimization method
[In this module, students will become familiar with estimating parameter confidence intervals when using the Monte Carlo method to estimate the best-fit parameters of a mathematical model to data.]
- Introduction
- Local curvature of likelihood GoF statistic close to minimum, and relationship to parameter uncertainties
- Estimating parameter uncertainties with the Hessian matrix
- A more simple method for estimating parameter uncertainties: the fmin plus a half method (aka graphical Monte Carlo method)
- Using the graphical Monte Carlo method with Least Squares
- Constructing 95% Confidence Intervals
- Example to show that graphical Monte Carlo method actually works
Protected: AML610 Fall 2014 class roster
ASU AML610 Spring 2013/Fall 2014 Syllabus
Objectives:
This course is meant to provide students in applied mathematics with the broad skill-set needed to optimize model parameters to relevant biological or epidemic data. The course will almost entirely be based on material posted on this website. Continue reading
Least Squares and Weighted Least Squares
[This is part of a series of modules on optimization methods]
The simplest, and often used, figure of merit for goodness of fit is the Least Squares statistic (aka Residual Sum of Squares), wherein the model parameters are chosen that minimize the sum of squared differences between the model prediction and the data. For N data points, Y^data_i (where i=1,…,N), and model predictions at those points, Y^model_i, the statistic is calculated as (note that the model prediction depends on the model parameters):
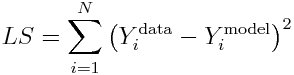
Optimizing model parameters to data (aka inverse problems)
[This presentation discusses methods commonly used to optimize the parameters of a mathematical model for population or disease dynamics to pertinent data. Parameter optimization of such models is complicated by the fact that usually they have no analytic solution, but instead must be solved numerically. Choice of an appropriate “goodness of fit” statistic will be discussed, as will the benefits and drawbacks of various fitting methods such as gradient descent, Markov Chain Monte Carlo, and Latin Hypercube and random sampling. An example of the application of the some of the methods using simulated data from a simple model for the incidence of a disease in a human population will be presented]
- Introduction
- Some simulated disease data in a human population
- Things to keep in mind when embarking on model parameter optimization
- Choice of an appropriate goodness of fit statistic
- Least Squares
- Poisson likelihood
- Negative Binomial likelihood
- Binomial likelihood
- Parameter optimization methods to optimize the goodness-of-fit statistic
- Gradient descent
- Simplex method
- Markov Chain Monte Carlo
- Graphical Monte Carlo: Latin hypercube sampling
- Graphical Monte Carlo: uniform random sampling
Fitting the parameters of an SIR model to influenza data using Least Squares and the graphical Monte Carlo method
[After reading this module, students should understand the Least Squares goodness-of-fit statistic. Students will be able to read an influenza data set from a comma delimited file into R, and understand the basic steps involved in the graphical Monte Carlo method to fit an SIR model to the data to estimate the R0 of the influenza strain by minimizing the Least Squares statistic. Students will be aware that parameter estimates have uncertainties associated with them due to stochasticity (randomness) in the data.]
A really good reference for statistical data analysis (including fitting) is Statistical Data Analysis, by G.Cowan.
Contents:
- Introduction
- Least squares goodness-of-fit statistic
- Finding the model parameters that minimize the Least Squares statistic: why we can’t just use linear regression methods for the models we usually use
- Monte Carlo parameter sweep method
- R code to fit to 2007-2008 confirmed influenza cases in Midwest
- Parameter estimates have uncertainties
- Potential pitfalls of using Least Squares
Introduction
When a new virus starts circulating in the population, one of the first questions that epidemiologists and public health officials want answered is the value of the reproduction number of the spread of the disease in the population (see, for instance, here and here).
The length of the infectious period can roughly be estimated from observational studies of infected people, but the reproduction number can only be estimated by examination of the spread of the disease in the population. When early data in an epidemic is being used to estimate the reproduction number, I usually refer to this as “real-time” parameter estimation (ie; the epidemic is still ongoing at the time of estimation).
Basic Unix
In the Arizona State University AML610 course “Computational and Statistical Methods in Applied Mathematics”, we will be ultimately be using super computing resources at ASU and the NSF XSEDE initiative to fit the parameters of a biological model to data. To do this, it is necessary to know basic Unix commands to copy, rename, and delete files and directories, and how to list directories and locate files. We will also be compiling all our C++ programs from the Unix shell, and in the command line directing the output of our programs to files.
Continue reading
SIR modelling of influenza with a periodic transmission rate
[After going through this module, students will be familiar with time-dependent transmission rates in a compartmental SIR model, will have explored some of the complex dynamics that can be created when the transmission is not constant, and will understand applications to the modelling of influenza pandemics.]
Contents:
- Introduction
- Periodic transmission rate
- The time-of-introduction of the virus is a parameter of the model
- Some conclusions we can draw from the model
- R code for SIR model simulation with a harmonic transmission rate
- Things to try
- More things to ponder
Introduction
Influenza is a seasonal disease in temperate climates, usually peaking in the winter. This implies that the transmission of influenza is greater in the winter (whether this is due to increased crowding and higher contact rates in winter, and/or due to higher transmissibility of the virus due to favorable environmental conditions in the winter is still being discussed in the literature). What is very interesting about influenza is that sometimes summer epidemic waves can be seen with pandemic strains (followed by a larger autumn wave). An SIR model with a constant transmission rate simply cannot replicate the annual dual wave nature of an influenza pandemic.
SIR infectious disease model with age classes
[After reading through this module, students should have an understanding of contact dynamics in a population with age structure (eg; kids and adults). You should understand how population age structure can affect the spread of infectious disease. You should be able to write down the differential equations of a simple SIR disease model with age structure, and you will learn in this module how to solve those differential equations in R to obtain the model estimate of the epidemic curve]
Contents:
- Introduction
- Population contact patterns
- An example of a contact matrix: kids and adults
- SIR model with age structure
- The reproduction number of the age structured SIR model
- R code for simulating an age structured SIR model
- Other kinds of class structure
- Things to try
Introduction
In a previous module I discussed epidemic modelling with a simple Susceptible, Infected, Recovered (SIR) compartmental model. The model presented had only a single age class (ie; it was homogenous with respect to age). But in reality, when we consider disease transmission, age likely does matter because kids usually make more contacts during the day than adults. The differences in contact patterns between age groups can have quite a profound impact on the model estimate of the epidemic curve, and also have implications for development of optimal disease intervention strategies (like age-targeted vaccination, social distancing, or closing schools).
Continue reading
Epidemic modelling with compartmental models using R
[After reading through this module you should have an intuitive understanding of how infectious disease spreads in the population, and how that process can be described using a compartmental model with flow between the compartments. You should be able to write down the differential equations of a simple disease model, and you will learn in this module how to numerically solve those differential equations in R to obtain the model estimate of the epidemic curve]
An excellent reference book with background material related to these lectures is Mathematical Epidemiology by Brauer et al.
Contents:
- Introduction
- Basic dynamics of infectious disease spread
- The SIR compartmental model of disease spread
- The SIR model system of equations
- Numerically solving the SIR model system of equations in R
- R code to model an influenza pandemic with an SIR model
- Further things you can explore
- Summary
Introduction
Models of disease spread can yield insights into the mechanisms and dynamics most important to the spread of disease (especially when the models are compared to epidemic data). With this improved understanding, more effective disease intervention strategies can potentially be developed. Sometimes disease models are also used to forecast the course of an epidemic, and doing exactly that for the 2009 pandemic was my introduction to the field of computational epidemiology.
There are lots of different ways to model epidemics, and there are several modules on this site on the topic, but let’s begin with one of the simplest epidemic models for an infectious disease like influenza: the Susceptible, Infected, Recovered (SIR) model.