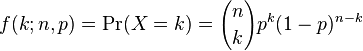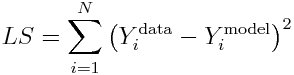[This is part of a series of modules on optimisation methods]
Latin hypercube sampling model parameter optimisation is a computationally intensive algorithm that nonetheless have several advantages over other optimisation methods for application to problems in mathematical epidemiology/biology in that it doesn’t require computation of a gradient.