The ASU Advanced Computing Center (A2C2) maintains the Saguaro distributed computing system, that currently has over 5,000 processor cores.
ASU students in the spring semester of AML610 should have already applied for and received an account on the Saguaro system (per the instructions of last month’s email describing how to apply for an account).
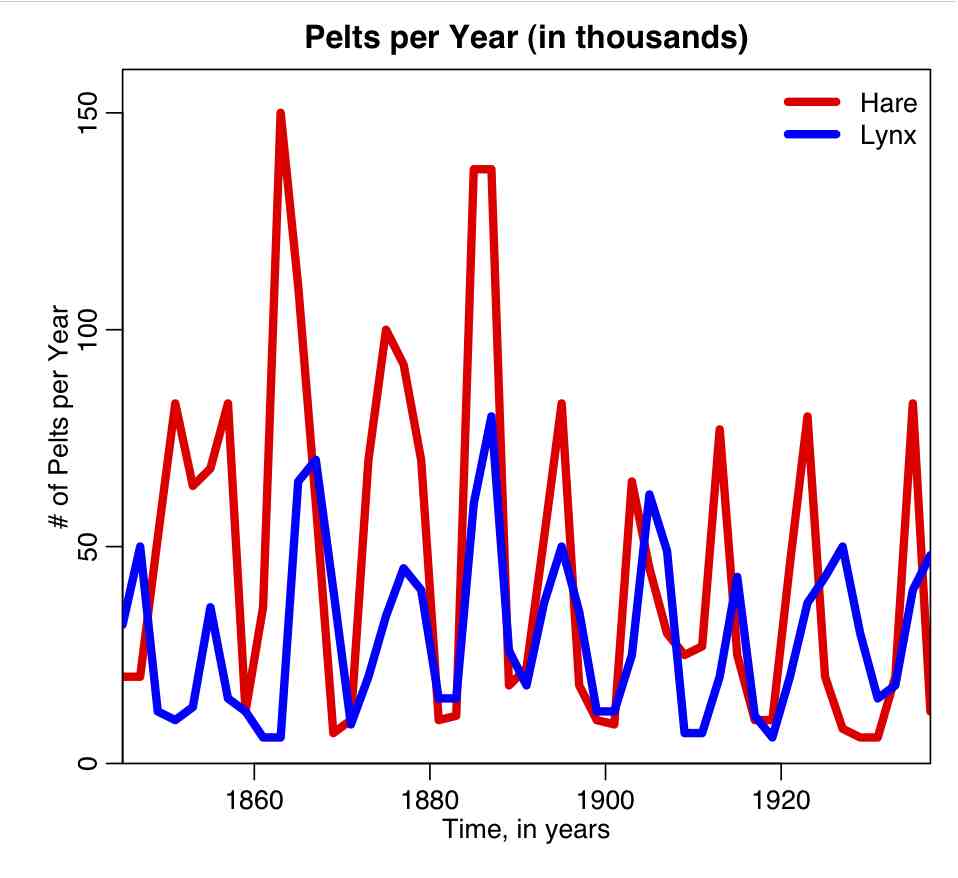
Saguaro allows you to simultaneously run multiple jobs in batch, directing standard output to a log file. For this course, we will be using Saguaro to solve a system of ODE’s under a hypothesis for the parameters and initial conditions values (either chosen in a parameter sweep, or randomly chosen within some range); the output of the ODE’s will then be compared to a data set, and a best-fit statistic (like Least Squares, Pearson chi-squared, or Maximum likelihood) computed. The parameter values and best-fit statistics are then printed to standard output.
Access to cloud computing resources, and knowledge of how to utilize those resources, has many different potential applications in modelling. Learning how to use Saguaro as a tool in solving problems related to this course can thus potentially open up many further avenues of future research to you.
Homework #5, due Thus April 18th, 2013 at 6pm. Data for the homework can be found here.
Continue reading →