
Author Archives: admin
Protected: Terrorism studies
Review of Probability Distributions, Basic Statistics, and Hypothesis Testing
Reply
[In this module, students will learn about probability distributions important to statistical modelling, focussing primarily on probability distributions that underlie the stochasticity in time series data.
In addition, in this course we will be learning how to formulate figure-of-merit statistics that can help to answer research questions like “Is quantity A significantly greater/less than quantity B?”, or “Does quantity X appear to be significantly related to quantity Y?”. As we are about to discuss, statistics that can be used to answer these types of questions do so using the underlying probability distribution to the statistic. Every statistic used for hypothesis testing has an underlying probability distribution.]
The difference between mathematical and statistical modelling (plus some more basics of R)
[In this module, we will discuss the difference between mathematical and statistical modelling, using pandemic influenza as an example. Example R code that solves the differential equations of a compartmental SIR model with seasonal transmission (ie; a mathematical model) is presented. Also provided are an example of how to download add-on library packages in R, plus more examples of reading data sets into R, and aggregating the data sets by some quantity (in this case, a time series of influenza data in Geneva in 1918, aggregated by weekday).
Delving into how to write the R code to solve systems of ODE’s related to a compartmental mathematical model is perhaps slightly off the topic of a statistical modelling course, but worthwhile to examine; as mathematical and computational modellers, usually your aim in performing statistical analyses will be to uncover potential relationships that can be included in a mathematical model to make that model better describe the underlying dynamics of the system]
- Introduction
- Susceptible Infected Recovered (SIR) influenza model with periodic transmission rate
- The time-of-introduction of the virus is a parameter of the harmonic SIR model
- R code for SIR model simulation with harmonic transmission rate
- Example of aggregating a data set by some quantity Continue reading
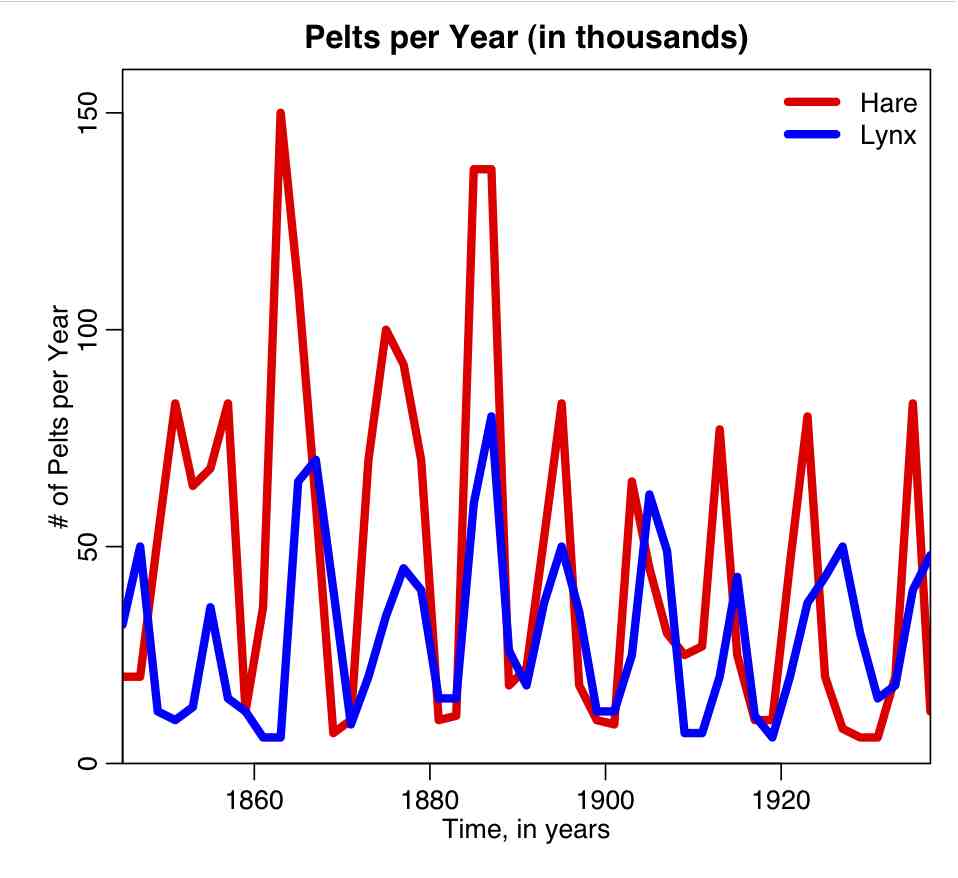
AML 610 Module XIII: Canadian hare lynx data
Canadian Hare Lynx Data
The file hare_lynx.txt contains data on the number of arctic hare and lynx pelts collected by the Hudson’s Bay company in Canada over the course of many years (data obtained from this website). Do you think the Lotka-Volterra model is an appropriate model to fit to these data?
The R script hare_lynx_plot.R plots the Hare Lynx data:
Meaning of bin-to-bin independence of data in a binned distribution
Link
What does it mean for data bins to be “independent” in a binned distribution (like, for instance, the time series of the number of newly identified disease cases each week)? This means that the stochastic variation data in the i^th bin is uncorrelated to the variation in the j^th bin. You should be aware that for epidemic data, this assumption is perhaps (probably) not satisfied, but the academic body of work related to this topic currently has not come up with a good way of assessing the bin-to-bin correlations, so for now we have little choice but to assume they are uncorrelated. Note that the assumption of independent bins underlies the Maximum Likelihood, Least Squares and Pearson chi-squared methods, unless special modification is made to those methods to take the correlations into account.
AML 610 Module XII: submitting jobs in batch to the ASU Saguaro distributed-computing system
The ASU Advanced Computing Center (A2C2) maintains the Saguaro distributed computing system, that currently has over 5,000 processor cores.
ASU students in the spring semester of AML610 should have already applied for and received an account on the Saguaro system (per the instructions of last month’s email describing how to apply for an account).
Saguaro allows you to simultaneously run multiple jobs in batch, directing standard output to a log file. For this course, we will be using Saguaro to solve a system of ODE’s under a hypothesis for the parameters and initial conditions values (either chosen in a parameter sweep, or randomly chosen within some range); the output of the ODE’s will then be compared to a data set, and a best-fit statistic (like Least Squares, Pearson chi-squared, or Maximum likelihood) computed. The parameter values and best-fit statistics are then printed to standard output.
Access to cloud computing resources, and knowledge of how to utilize those resources, has many different potential applications in modelling. Learning how to use Saguaro as a tool in solving problems related to this course can thus potentially open up many further avenues of future research to you.
Homework #5, due Thus April 18th, 2013 at 6pm. Data for the homework can be found here.
AML610 module XI: practical problems when connecting deterministic models to data
Some (potentially) useful utilities for random number generation and manipulating vectors in C++
I’ve written some C++ code mainly related to vectors; calculating the weighted mean, running sum, extracting every nth element, etc). There are also utilities related to random number generation from various probability distributions, and methods to calculate the CDF of various probability distributions.
The file UsefulUtils.h and UsefulUtils.cpp contain source code of a class that contains these utilities that can be useful when performing compartmental modelling in C++. These utilities will be used extensively in the examples that will be presented in this, and later, modules. The file example_useful_utils.cpp gives examples of the use of the class. It can be compiled with the makefile makefile_use with the command
make -f makefile_use example_useful_utils
Homework #4, due April 3rd, 2013 at 6pm. The data for the homework can be found here.
Numerical methods to solve ordinary differential equations
After going through this module, students will be familiar with the Euler and Runge-Kutta methods for numerical solution of systems of ordinary differential equations. Examples are provided to show students how complementary R scripts can be written to help debug Runge-Kutta methods implemented in C++.
Contents
- Euler’s method (finite difference method)
- Using the Euler method to solve dN/dt = rho*N
- Implementing the Euler method in C++
- Comparison of the output of the C++ and R programs implementing the Euler method to solve dN/dt=rho*N
- Dynamic time step calculation in the Euler method
- Runge-Kutta method
- Example of implementation of Runge Kutta in C++: Lotka-Volterra predator prey model
ASU AML 610 Module IX: Introduction to C++ for computational epidemiologists
After going through this module, students should be familiar with basic skills in C++ programming, including the structure of a basic program, variable types, scope, functions (and function overloading), control structures, and the standard template library.
- Hello world
- Variable types
- Strings
- Boolean logic
- Scope of variables
- Introduction to functions
- Arguments to main
- Control structures (if/then/else, while, for loops)
- Functions, pass by value
- Functions, pass by reference
- Overloading functions
- The standard template library: vectors
- Vectors in multi-dimensions
- Parsing data from comma delimited files
- Makefiles
- Introduction to classes and objects
So far in this course we have used R to explore methods related to fitting model parameters to data (in particular, we explored the Simplex method for parameter estimation). As we’ve shown, parameter estimation can be a very computationally intensive process.
When you use R, it gives you a prompt, and waits for you to input commands, either directly through the command line, or through an R script that you source. Because R is a non-compiled language, and instead interprets code step-by-step, it does not have the ability to optimize calculations by pre-processing the code.
In contrast, compiled programming languages like C, java, or C++ (to name just a few) use a compiler to process the code, and optimize the computational algorithms. In fact, most compilers have optional arguments related to the level of optimization you desire (with the downside that the optimization process can be computationally intensive). Optimized code runs faster than non-optimized code.
ASU AML 610 Module VIII: Fitting to initial exponential rise of epidemic curves
In this module students will compare the performance of several fitting methods (Least squares, Pearson chi-squared, and likelihood fitting methods) in estimating the rate of exponential rise in initial epidemic incidence data. Students will learn about the properties of good estimators (bias and efficiency).
A good reference source for this material is Statistical Data Analysis, by G.Cowan
Another good reference source (in a very condensed format) for statistical data analysis methods can be found here.
Contents:
Introduction
Properties of good estimators
Generating simulated exponential rise data
Estimation of the rate of exponential rise: Least Squares
Estimation of the rate of exponential rise: Pearson chi-squared
The Poisson maximum likelihood method
Estimation of parameter confidence intervals: any maximum likelihood method
Estimation of the rate of exponential rise: Poisson maximum likelihood method
Testing for over- or under-dispersion.
Correcting for over- or under-dispersion
Better method for determination of parameter estimates and their covariance when using the Pearson chi-squared method
Fitting the parameters of an SIR model to influenza data using Least Squares and the graphical Monte Carlo method
[After reading this module, students should understand the Least Squares goodness-of-fit statistic. Students will be able to read an influenza data set from a comma delimited file into R, and understand the basic steps involved in the graphical Monte Carlo method to fit an SIR model to the data to estimate the R0 of the influenza strain by minimizing the Least Squares statistic. Students will be aware that parameter estimates have uncertainties associated with them due to stochasticity (randomness) in the data.]
A really good reference for statistical data analysis (including fitting) is Statistical Data Analysis, by G.Cowan.
Contents:
- Introduction
- Least squares goodness-of-fit statistic
- Finding the model parameters that minimize the Least Squares statistic: why we can’t just use linear regression methods for the models we usually use
- Monte Carlo parameter sweep method
- R code to fit to 2007-2008 confirmed influenza cases in Midwest
- Parameter estimates have uncertainties
- Potential pitfalls of using Least Squares
Introduction
When a new virus starts circulating in the population, one of the first questions that epidemiologists and public health officials want answered is the value of the reproduction number of the spread of the disease in the population (see, for instance, here and here).
The length of the infectious period can roughly be estimated from observational studies of infected people, but the reproduction number can only be estimated by examination of the spread of the disease in the population. When early data in an epidemic is being used to estimate the reproduction number, I usually refer to this as “real-time” parameter estimation (ie; the epidemic is still ongoing at the time of estimation).
ASU AML 610: probability distributions important to modelling in the life and social sciences
[After reading this module, students should be familiar with probability distributions most important to modelling in the life and social sciences; Uniform, Normal, Poisson, Exponential, Gamma, Negative Binomial, and Binomial.]
Contents:
Introduction
Probability distributions in general
Probability density functions
Mean, variance, and moments of probability density functions
Mean, variance, and moments of a sample of random numbers
Uncertainty on sample mean and variance, and hypothesis testing
The Poisson distribution
The Exponential distribution
The memory-less property of the Exponential distribution
The relationship between the Exponential and Poisson distributions
The Gamma and Erlang distributions
The Negative Binomial distribution
The Binomial distribution
There are various probability distributions that are important to be familiar with if one wants to model the spread of disease or biological populations (especially with stochastic models). In addition, a good understanding of these various probability distributions is needed if one wants to fit model parameters to data, because the data always have underlying stochasticity, and that stochasticity feeds into uncertainties in the model parameters. It is important to understand what kind of probability distributions typically underlie the stochasticity in epidemic or biological data.
Continue reading
Basic Unix
In the Arizona State University AML610 course “Computational and Statistical Methods in Applied Mathematics”, we will be ultimately be using super computing resources at ASU and the NSF XSEDE initiative to fit the parameters of a biological model to data. To do this, it is necessary to know basic Unix commands to copy, rename, and delete files and directories, and how to list directories and locate files. We will also be compiling all our C++ programs from the Unix shell, and in the command line directing the output of our programs to files.
Continue reading
Good practices in producing plots
Years ago I once had a mentor tell me that one of the hallmarks of a well-written paper is the figures; a reader should be able to read the abstract and introduction, and then, without reading any further, flip to the figures and the figures should provide much of the evidence supporting the hypothesis of the paper. I’ve always kept this in mind in every paper I’ve since produced. In this module, I’ll discuss various things you should focus on in producing good, clear, attractive plots.
Good programming practices (in any language)
Easy readability, ease of editing, and ease of re-usability are things to strive for in code you write in any language. Achieving that comes with practice, and taking careful note of the hallmarks of tidy, readable, easily editable, and easily re-usable code written by other people.
While I’m certainly not perfect when it comes to utmost diligence in applying good programming practices, I do strive to make readable and re-useable code (if only because it makes my own life a lot easier when I return to code I wrote a year earlier, and I try to figure out what it was doing).
In the basics_programming.R script that I make use of some good programming practices that ensure easy readability. For instance, code blocks that get executed within an if/then statement, for loops, or while loops are indented by a few spaces (usually two or three… be consistent in the number of indent spaces you use). This makes it clear when reading the code which nested block of code you are looking at. I strongly advise you to not use tabs to indent code. To begin with, every piece of code I’ve ever had to modify that had tabs for indent also used spaces here and there for indentation, and it makes it a nightmare to edit and have the code remain easily readable. Also, if you have more than one or two nested blocks of code, using tabs moves the inner blocks too far over to make the code easily readable.
In the R script sir_agent_func.R I define a function. Notice in the script that instead of putting all the function arguments on one long line, I do it like this:
SIR_agent = function(N # population size
,I_0 # initial number infected
,S_0 # initial number susceptible
,gamma # recovery rate in days^{-1}
,R0 # reproduction number
,tbeg # begin time of simulation
,tend # end time of simulation
,delta_t=0 # time step (if 0, then dynamic time step is implemented)
){
This line-by-line argument list makes it really easy to read the arguments (and allows inline descriptive comments). It also makes it really easy to edit, because if you want to delete an argument, it is simple as deleting that line. If you want to add an argument, add a line to the list.
Descriptive variable names are a good idea because they make it easier for someone else to follow your code, and/or make it easier to figure out what your own code did when you look at it 6 months after you wrote it.
Other good programming practices are to heavily comment code, with comment breaks that clearly delineate sections of code that do specific tasks (this makes code easy to read and follow). I like to put such comments “in lights” (ie; I put a long line of comment characters both above and below the comment block, to make it stand out in the code). If the comments are introducing a function, I will usually put two or three long lines of comment characters at the beginning of the comment block; it makes it clear and easy to see when paging through code where the functions are defined.
In-line comments are also very helpful to make it clear what particular lines of code are doing.
A good programming practice that makes code much easier to re-use is to never hard-code numbers in the program. For instance, at the top of the basics_programming.R script I create a vector that is n=1000 elements long. In the subsequent for loop, I don’t have
for (i in 1:1000){}
Instead I have
for (i in 1:n){}
This makes that code reusable as-is if I decide to use it to loop over the elements of a vector with a different length. All I have to do is change n to the length of the new vector. Another example of not hard-coding numbers is found in the code associated with the while loop example.
As an aside here, I should mention that in any programming language you should never hard-code the value of a constant like π (as was pointed out in basics.R, it is a built-in constant in R, so you don’t need to worry about this for R code). In other languages, you should encode pi as pi=acos(-1.0), rather than something like pi=3.14159. I once knew a physics research group that made the disastrous discovery that they had a typo in their hard-coded value of pi… they had to redo a whole bunch of work once the typo was discovered.
Notice in the script that I have a comment block at the top of basics_programming.R that explains what the script does, gives the date of creation and the name of the person who wrote the script (ie; me). It also gives the contact info for the author of the script, and copyrights the script. Every script or program you write should have that kind of boilerplate at the top (even if you think the program you are writing will only be used by you alone… you might unexpectedly end up sharing it with someone, and/or the boilerplate makes it clear that the program is *your* code, and that people just can’t pass it off as their own it if they come across it). It also helps you keep track of when you wrote the program.
Stochastic epidemic modelling with Agent Based Models
[After reading this module, you will be aware of the limitations of deterministic epidemic models, like the SIR model, and understand when stochastic models are important. You will be introduced to three different methods of stochastic modelling, and understand the appropriate applications of each. By the end of this module, you will be able to implement a simple Agent Based stochastic model in R.]
Contents:
SIR modelling of influenza with a periodic transmission rate
[After going through this module, students will be familiar with time-dependent transmission rates in a compartmental SIR model, will have explored some of the complex dynamics that can be created when the transmission is not constant, and will understand applications to the modelling of influenza pandemics.]
Contents:
- Introduction
- Periodic transmission rate
- The time-of-introduction of the virus is a parameter of the model
- Some conclusions we can draw from the model
- R code for SIR model simulation with a harmonic transmission rate
- Things to try
- More things to ponder
Introduction
Influenza is a seasonal disease in temperate climates, usually peaking in the winter. This implies that the transmission of influenza is greater in the winter (whether this is due to increased crowding and higher contact rates in winter, and/or due to higher transmissibility of the virus due to favorable environmental conditions in the winter is still being discussed in the literature). What is very interesting about influenza is that sometimes summer epidemic waves can be seen with pandemic strains (followed by a larger autumn wave). An SIR model with a constant transmission rate simply cannot replicate the annual dual wave nature of an influenza pandemic.
SIR infectious disease model with age classes
[After reading through this module, students should have an understanding of contact dynamics in a population with age structure (eg; kids and adults). You should understand how population age structure can affect the spread of infectious disease. You should be able to write down the differential equations of a simple SIR disease model with age structure, and you will learn in this module how to solve those differential equations in R to obtain the model estimate of the epidemic curve]
Contents:
- Introduction
- Population contact patterns
- An example of a contact matrix: kids and adults
- SIR model with age structure
- The reproduction number of the age structured SIR model
- R code for simulating an age structured SIR model
- Other kinds of class structure
- Things to try
Introduction
In a previous module I discussed epidemic modelling with a simple Susceptible, Infected, Recovered (SIR) compartmental model. The model presented had only a single age class (ie; it was homogenous with respect to age). But in reality, when we consider disease transmission, age likely does matter because kids usually make more contacts during the day than adults. The differences in contact patterns between age groups can have quite a profound impact on the model estimate of the epidemic curve, and also have implications for development of optimal disease intervention strategies (like age-targeted vaccination, social distancing, or closing schools).
Continue reading
Compartmental modelling without calculus
In another module on this site I describe how an epidemic for certain kinds of infectious diseases (like influenza) can be modelled with a simple Susceptible, Infectious, Recovered (SIR) model. Readers who have not yet been exposed to calculus (such as junior or senior high school students) may have been daunted by the system of differential equations shown in that post. However, with only a small amount of programming experience in R, students without calculus can still easily model epidemics, or any other system that can be described with a compartmental model. In this post I will show how that is done.
Continue reading